Compétition de prévisions de ventes : M5 Forecasting Accuracy
Au printemps 2020, pendant le confinement, j’ai participé au concours M5 Forecasting Accuracy sur Kaggle. Presque un an après le début du concours, je me suis rendu compte que je n’en avais pas parlé ni partagé mon code. La plupart des solutions partagées sur Kaggle sont en Python, j’ai pensé que cela pouvait intéresser les utilisateurs de R qui souhaitent construire un modèle de prévision de ventes pour voir un exemple en R.
Qu’est-ce que le concours M5 ?
Les compétitions M sont organisées par Spyros Makridakis pour évaluer et comparer différentes méthodes de prévision sur des problèmes du monde réel. Le premier concours a eu lieu en 1982, avec 1001 séries temporelles, suivi d’un concours environ toutes les décennies jusqu’au M4 en 2018 avec 100 000 séries temporelles, et l’utilisation d’un algorithme d’apprentissage automatique (Machine Learning, ML) qui s’est avéré peu performant par rapport aux méthodes statistiques ou hybrides utilisant les deux, statistique et ML.
La 5ème édition (M5) s’est déroulée pendant 4 mois du 3 mars au 30 juin 2020. Les données sont fournies par Walmart, et se composent de 3049 articles de 3 catégories et 7 départements, dans 10 magasins dans 3 états différents, résultant de 30490 séries temporelles hiérarchiques, avec 1941 jours d’historique.
L’objectif du concours M5 est de prévoir les ventes des prochains 28 jours pour tous les articles, et à différents niveaux d’agrégation (état, magasin, catégorie, département, état/catégorie, état/département, magasin/catégorie, magasin/département etc.) résultant d’un total de 42840 séries temporelles.
Voici la vue de la hiérarchie, cliquez sur les noeuds pour développer le sous-niveau :
L’une des particularités de ce concours est la métrique d’évaluation. La précision est évaluée par l’erreur quadratique moyenne échelonnée (RMSSE), pondérée par les ventes en dollars réelles cumulatives, sur la base des 28 dernières observations. Ceci se justifie pour donner une plus grande importance aux séries qui représentent les ventes plus élevées. En revanche, c’est une métrique difficile à utiliser comme fonction objective notamment lors de la décomposition des données pour former différents modèles, par magasin par exemple.
Donc les 3 caractéristiques principales du concours M5 Forecasting Accuracy :
- Séries chronologiques hiérarchiques
- Ventes intermittentes (faible niveau de ventes avec de nombreux jours sans ventes)
- Métrique d’évaluation complexe WRMSSE (Weighted Root Mean Squared Scaled Error)
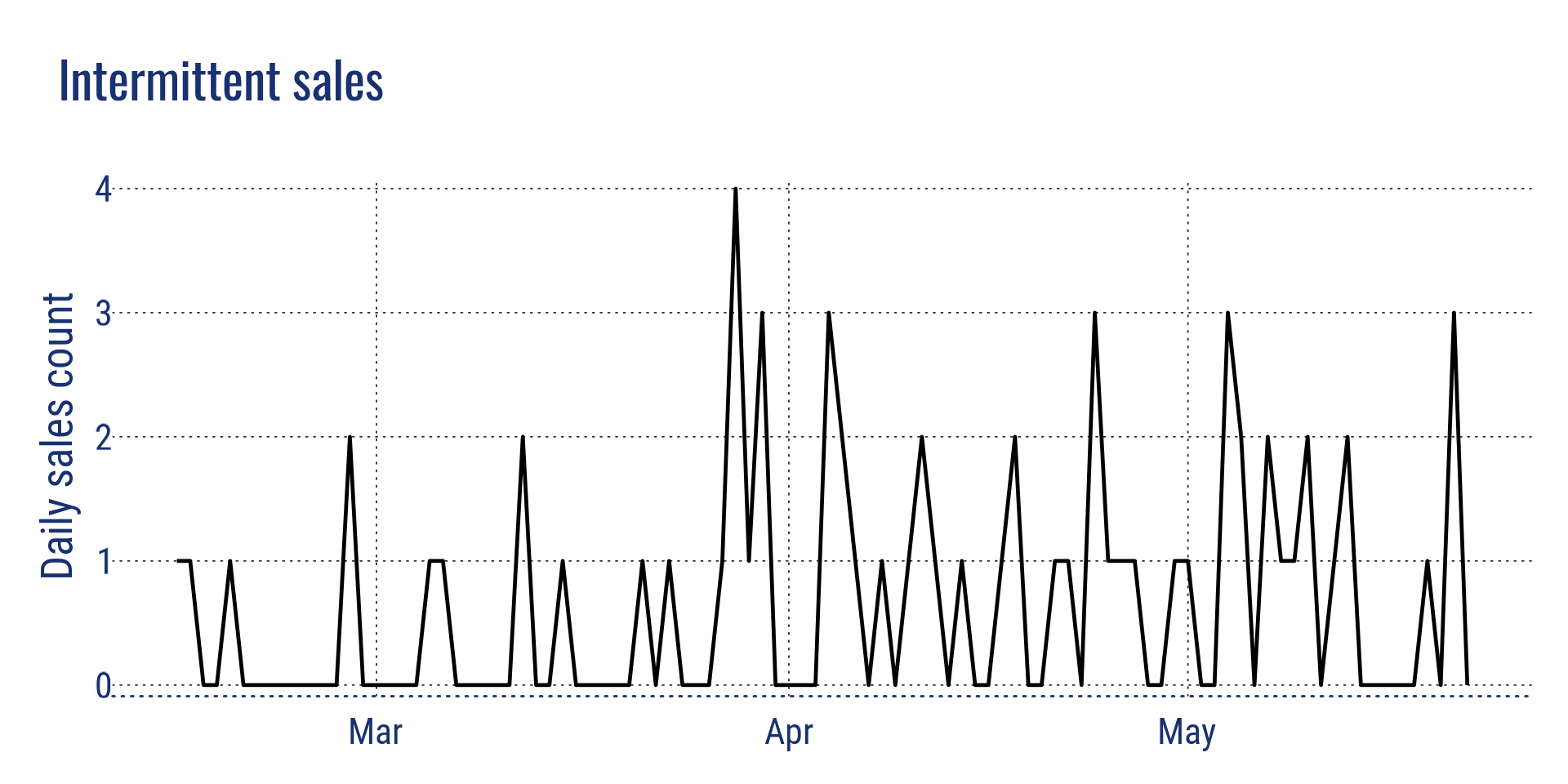
Intermittent sales
La compétition s’est déroulée en deux phases :
- Dans un premier temps les données de validation étaient disponibles, avec un historique du 29/01/2011 au 24/04/2016, à prévoir pour la période du 25/04/2016 au 22/05/2016 (période de validation utilisée pour le classement public).
- Le 1er juin, les valeurs réelles pour la période de validation ont été publiées, que nous avons pu utiliser pour analyser et évaluer notre modèle, et pour prévoir les 28 prochains jours du 23/05/2016 au 19/06/2016, qui est le période qui est évaluée pour le score final dans le classement privé.
Présentation de mon travail
Note rapide
Ci-dessous, je vais vous expliquer les principes que j’ai utilisés, les difficultés que j’ai rencontrées dans mon environnement, qui peuvent ne pas s’appliquer au vôtre, et comment je les ai résolues, afin de mieux comprendre le fonctionnement du code si vous souhaitez expérimenter avec. Cet article n’est donc pas un tuto sur comment gagner un concours Kaggle, ou une analyse de la meilleure façon de gagner le concours M5, mais un retour d’expérience et un guide pour comprendre le code que je publie.
Premiers pas
J’ai profité de la compétition pour expérimenter différentes techniques et algorithmes. Après une analyse exploratoire des données, j’ai commencé avec un modèle naïf, en utilisant les données du mois précédent, mélangées aux données de l’année précédente, pour avoir une base de référence pour le score, ce modèle a donné un WRMSSE de 0,93946.
Les modèles Arima ne fonctionnaient pas bien sur les séries temporelles intermittentes, et étaient très longs pour traiter 30490 séries temporelles, je les ai abandonnés rapidement, ainsi que le lissage exponentiel qui laissait peu de place à l’amélioration. Je me suis concentré uniquement sur les algorithmes gradient boosting decision tree, avec XGBoost et LightGBM en premier, et uniquement sur lightGBM ensuite car il donnait de meilleur résultats.
Défis techniques
La première approche consistait à créer un modèle, entraîné sur l’ensemble des données, qui prévoirait les 28 jours pour toutes les séries temporelles à la fois. J’ai rapidement eu un problème de mémoire avec cette approche. Je ne pouvais utiliser que le kernel Kaggle ou mon ordinateur portable, qui ont tous deux une limite de mémoire de 16 Go. 30490 séries temporelles avec 1941 jours d’histoire donnent un dataframe avec 59 181 090 observations. Il n’était possible de créer que peu de nouvelles variables avant de dépasser la limite de mémoire, ce qui rendait difficile l’amélioration du modèle.
Une autre difficulté à laquelle je ne m’attendais pas, c’est que le résultat avec le Kernel Kaggle était complètement différent (pire) que sur mon propre ordinateur. J’ai utilisé les données d’un kernel public en Python, en utilisant exactement les mêmes variables et hyperparamètres que le noyau Python, et j’ai obtenu un score similaire sur ma machine, mais un très mauvais score lorsqu’il s’exécutait sur Kaggle. Je n’ai donc pas fait confiance à la version Kaggle de LightGBM pour R et j’ai décidé de n’utiliser que mon ordinateur portable.
Ainsi, ces deux difficultés font partie des choix qui conduisent à la solution finale :
- Choix conceptuels :
- Divisier les données et construire un modèle par division (split)
- Automatiser, car j’exécute sur mon ordinateur portable, et pour une question de temps je n’expérimente que sur un seul split, et je dois exécuter la nuit pour tout les autres split (environ 8 heures).
- Choix techniques :
- Utiliser tidyverse pour les fonctionnalités basées sur chaque split et data.table pour les fonctionnalités basées sur l’ensemble des données, car data.table met à jour par référence en utilisant moins de mémoire.
- Enregistrer les variables sur le disque pour une utilisation ultérieure et les supprimer de la mémoire
- Ne pas utiliser de framework (type tidymodels, mlr etc) afin de contrôler l’utilisation de la mémoire, ce qui oblige à plonger plus profondément dans LightGBM pour coder toutes les étapes.
Fonctionnement
Le code et les étapes pour l’exécuter se trouvent sur mon dépôt github :
Le coeur du modèle
Split par magasin
Les données sont divisées par store_id, ce qui signifie qu’il y a 10 modèles pour chaque période (validation et évaluation), donc pour obtenir une soumission complète, il y a un total de 20 modèles, qui génèrent 20 fichiers qui doivent être fusionnés dans la soumission finale du fichier .
Avec cette approche, je pouvais traiter le problème de la mémoire. Cependant, le modèle manquait d’informations provenant du reste des données, par exemple le volume de vente pour cet article au niveau de l’État, la vente moyenne pour cette catégorie dans tous les magasins, etc.
J’ai donc créé un script distinct qui crée les fonctionnalités en fonction de toutes les données une fois, et qui sont ajoutées aux données du split actuel à la fin du processus d’ingénierie des fonctionnalités (feature engineering) pour le magasin.
Prévisions hebdomadaires
J’ai utilisé une prévision hebdomadaire, je vais donc utiliser certaines données de la semaine précédente pour générer des variables pour la prévision de la semaine en cours. La principale raison en est que les ventes sont plus corrélées aux ventes de la semaine précédente qu’au mois précédent. Il y a quand même un gros problème avec ça. Comme nous devons prévoir pour 28 jours, soit 4 semaines, la première semaine utilisera les vraies valeurs de la semaine précédente. La deuxième semaine utilise les vraies valeurs pour les variables avec un décalage > 7, mais doit utiliser les valeurs prédites pour les variables avec un décalage < 7, ce qui augmente l’incertitude et conduit à des prévisions moins précises pour les semaines suivantes.
Pour réduire l’impact, toutes les fonctionnalités basées sur la semaine précédente sont des fonctionnalités glissantes utilisant au moins une fenêtre de 7 jours, pour lisser les prédictions. Ainsi, les prédictions ne sont pas utilisées directement comme valeur de décalage, ce qui leur donneraient trop d’importance lors de l’entraînement de l’algorithme et seraient trop imprécises pour les prédictions des semaines suivantes, mais elles sont utilisées pour construire des fonctionnalités glissantes sur une période de 7, 14, 28 jours.
Les valeurs de décalage sont utilisées directement uniquement avec les valeurs réelles (décalage > 28).
De plus, pour la prédiction de chaque semaine, j’avais besoin de recalculer les variables hebdomadaires en utilisant les prévisions pour la semaine n-1, ce qui est fait par la fonction de prédiction. Donc, si vous utilisez ce code et modifiez le calcul de certaines variables hebdomadaires, pensez également à adapter le code dans la fonction de prédiction, sinon ces variables n’auront que des NAs.
J’ai pensé qu’il était intéressant d’utiliser cette technique car elle peut s’appliquer à des cas concrets en entreprise lorsque vous avez besoin de prévisions plus précises pour l’horizon ferme, et mettre à jour les prévisions périodiquement.
Voici une explication visuelle des prévisions hebdomadaires à 28 jours sur un seule variable :
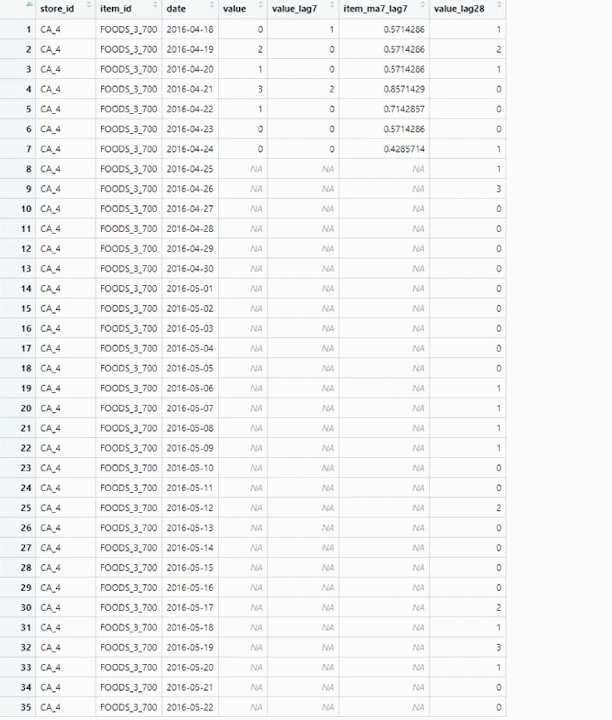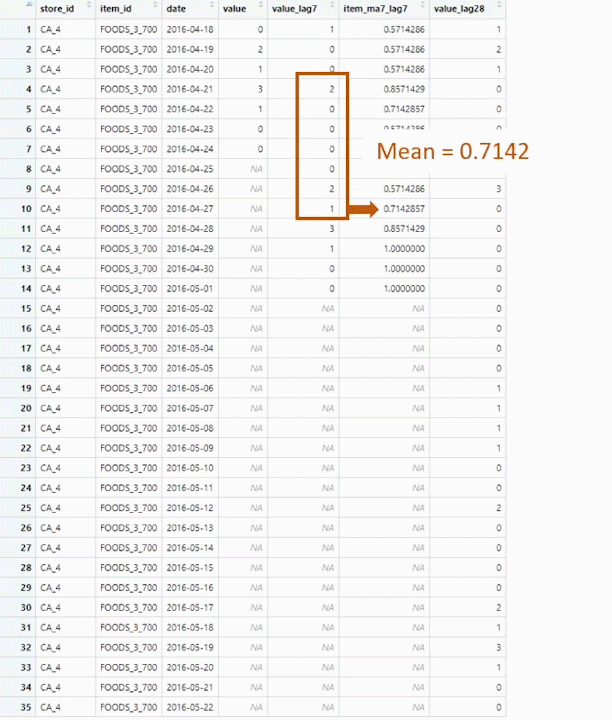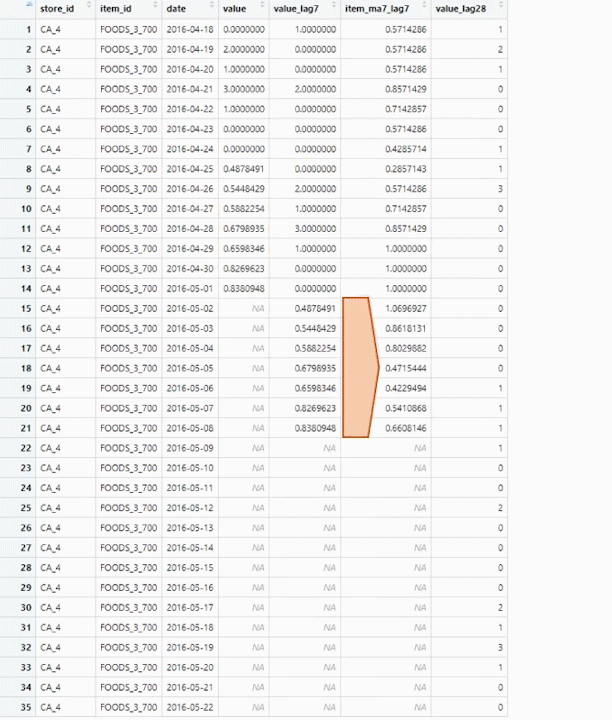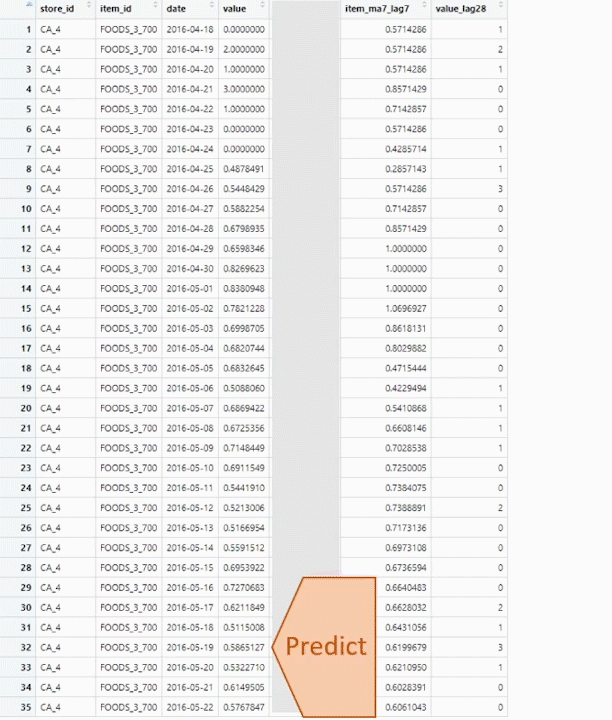
weekly forecast explanation
Cette prévision hebdomadaire est la raison pour laquelle nous voyons une différence du RMSE entre l’utilisation des données pour la validation pendant le processus d’entraînement (qui utilisent les variables basées sur les vraies valeurs de la semaine dernière) et la prédiction pour la même période en utilisant la prévision hebdomadaire qui recréent les variables à l’aide des prédictions.
Par exemple dans le magasin CA_4 :
- RMSE lors de la validation : 1,33
- RMSE prédiction hebdomadaire sur test : 1,39
- RMSE sur les nouvelles données : 1:43 (calculé après la diffusion des vraies valeurs)
Vous devriez donc vous fier davantage au RMSE basé sur la prédiction hebdomadaire qui sera plus proche de ce à quoi vous pouvez vous attendre pour la prédiction sur les nouvelles données.
Ingénierie des fonctionnalités
Comme je l’ai expliqué plus haut, il existe deux types de fonctionnalités :
- Les variables créées en utilisant toutes les données à différents niveaux d’agrégation. Ils sont créés une fois par un script séparé et utilisés pour chaque modèle
- Les fonctionnalités créées au niveau du magasin, qui sont créées pour chaque division.
Les variables sont basées sur :
- valeurs de décalage pour le décalage > 28 jours et fonction mobiles (moyennes et sommes mobiles) avec différentes tailles de fenêtre
- moyenne mobile et écart type mobile pour les valeurs de décalage < 28 jours avec différentes tailles de fenêtre
- fonctionnalités basées sur le calendrier telles que le jour de la semaine, est-ce un week-end ?, les jours fériés, le mois, un événement spécial
- date de sortie de l’article
- caractéristiques des prix, min, max, moyenne, sd, normalisé, différence de prix avec la veille, nombre de magasins avec ce prix
- encodage moyen (mean encoding)
- diverses statistiques
Les variables créées sur l’ensemble des données sont principalement des fonctionnalités d’encodage moyen pour les différents niveaux d’agrégation.
Vous pouvez jouer avec et ajouter de nouvelles variables, n’oubliez pas d’adapter la fonction de prédiction pour les recalculer si vous modifiez une variable qui utilise un décalage < 28 comme discuté précédemment.
Hyperparamètres
J’ai fait un réglage d’hyperparamètre avec un objectif “poisson”, qui donnait de bons résultats. Mais après avoir essayé un autre ensemble de paramètres suggérés par certaines équipes sur Kaggle, j’ai utilisé les mêmes hyperparamètres qui fonctionnaient mieux.
L’objectif utilisé est un objectif “tweedie”, plus adapté à une distribution avec des ventes intermittentes avec beaucoup de valeurs nulles. La distribution de Poisson est un cas particulier de distribution de Tweedie avec une puissance = 1.
J’ai utilisé deux ensembles d’hyperparamètres car j’ai trouvé que la prévision était meilleure avec une puissance = 1,1 sur certains magasins et meilleure avec une puissance = 1,2 sur d’autres.
J’ai utilisé un simple RMSE pour les métriques, car il est plus simple à utiliser et à interpréter, et je ne pouvais pas utiliser le WRMSSE avec un modèle par magasin. J’ai trouvé qu’il évoluait dans le même sens que le WRMSSE la plupart du temps. Ainsi, lorsque j’ai amélioré le modèle et obtenu un meilleur RMSE, la plupart du temps, le WRMSSE s’améliore également lorsque je soumettais les prévisions (pas dans la même proportion cependant).
Validation croisée
En raison du temps qu’il faut pour entrainer les modèles sur tous les magasins (8 heures), j’ai utilisé une simple division train / test pour tester de nouvelles fonctionnalités et améliorer le modèle. Une validation croisée k-fold aurait pris trop de temps (j’avais aussi besoin d’utiliser mon ordinateur!).
Cependant, régulièrement, je testais la cohérence du modèle en entraînant et en prédisant sur d’autres périodes. Vous pouvez facilement adapter la période d’entraînement et de test avec deux paramètres “test_date” et “valid_date”.
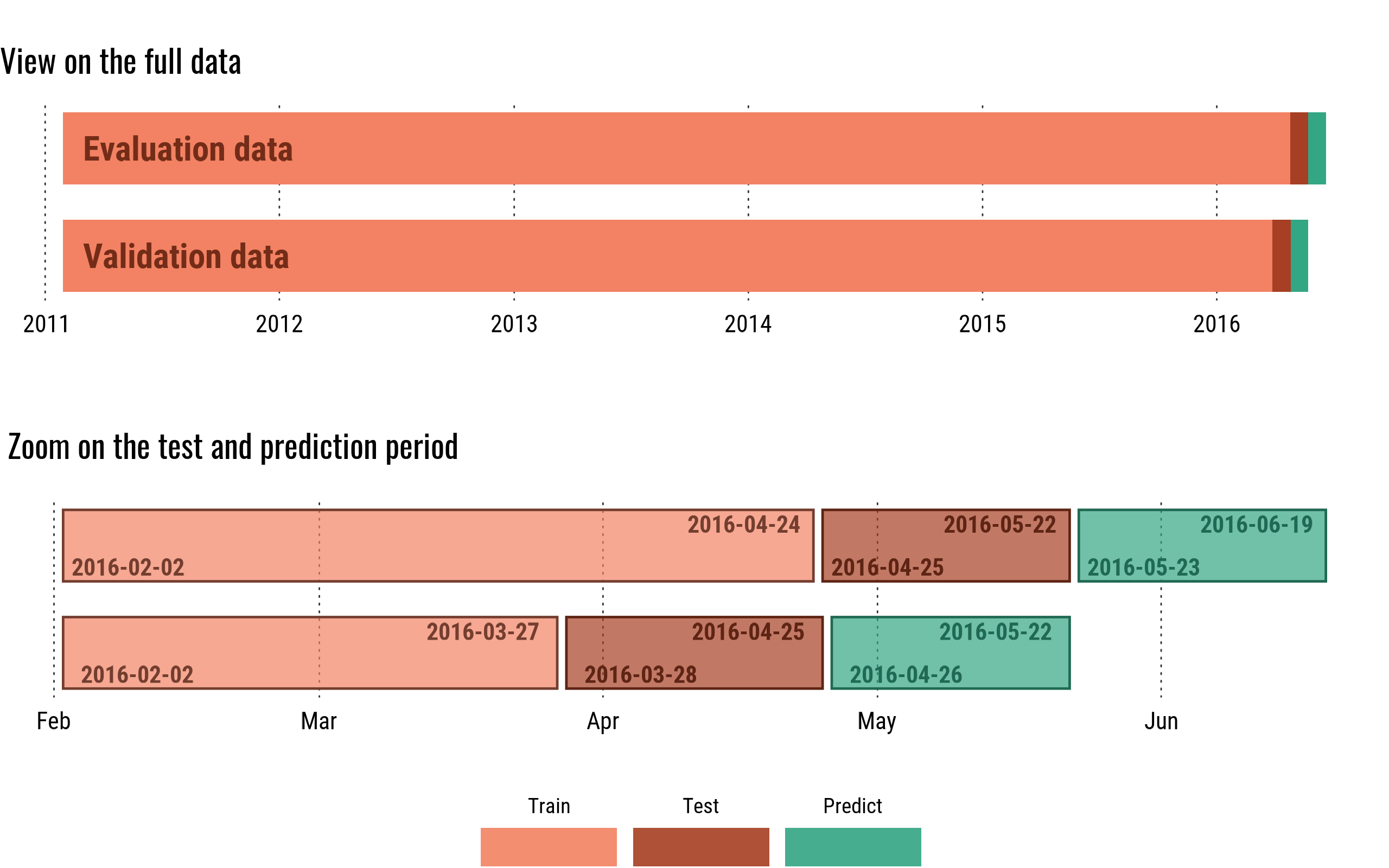
cross validation period
Affichage
Version interactive
La version interactive que vous exécutez dans RStudio donnera les sorties suivantes :
- Le RMSE pour les données de test
- Le RMSE pour les données de validation
- La courbe d’apprentissage
- L’importance des variables
- Un graphique interactif avec les vraies valeurs et prédictions pour tous les départements du magasin sur le jeu de données de validation
- Un graphique interactif avec les prédictions pour tous les départements du magasin sur le jeu de données d’évaluation
Ci-dessous quelques exemples pour le magasin CA_4, vous pouvez cliquer sur les images pour les voir en taille réelle.
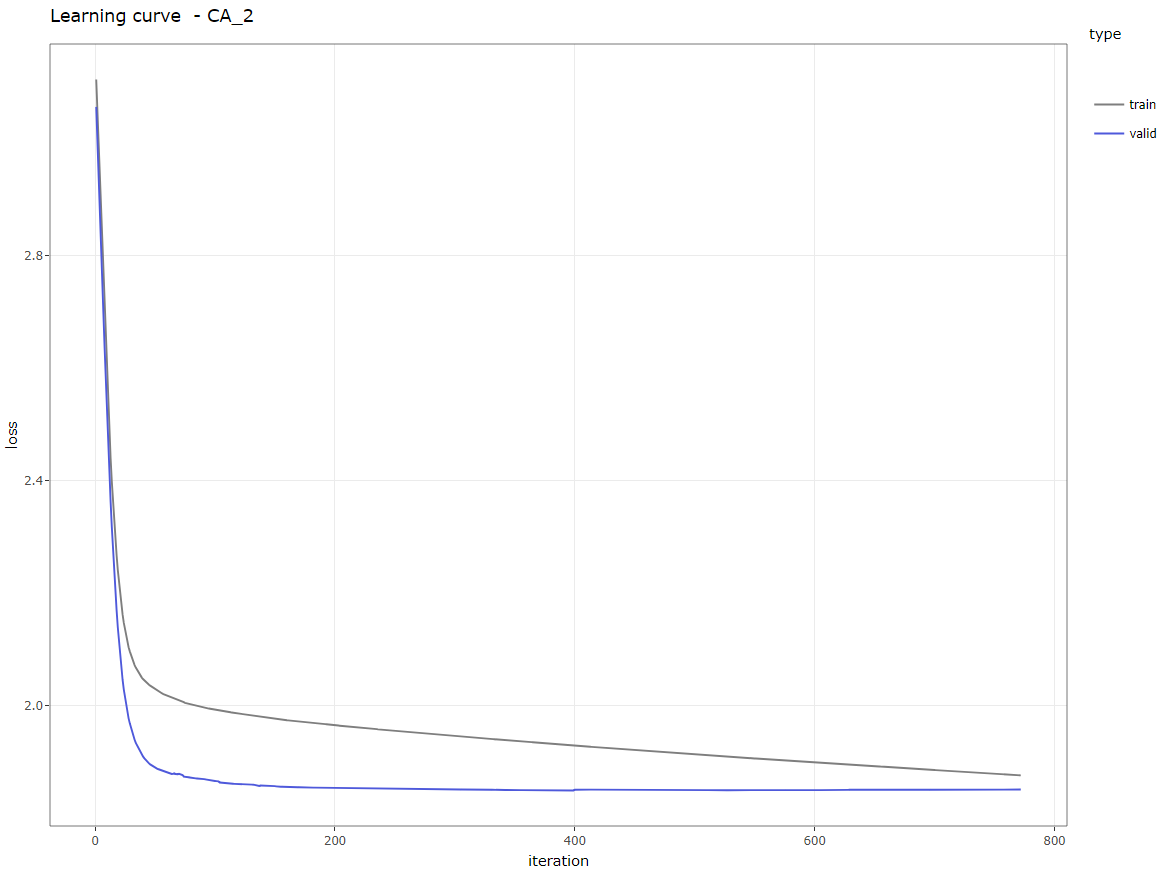
Courbe d’apprentissage
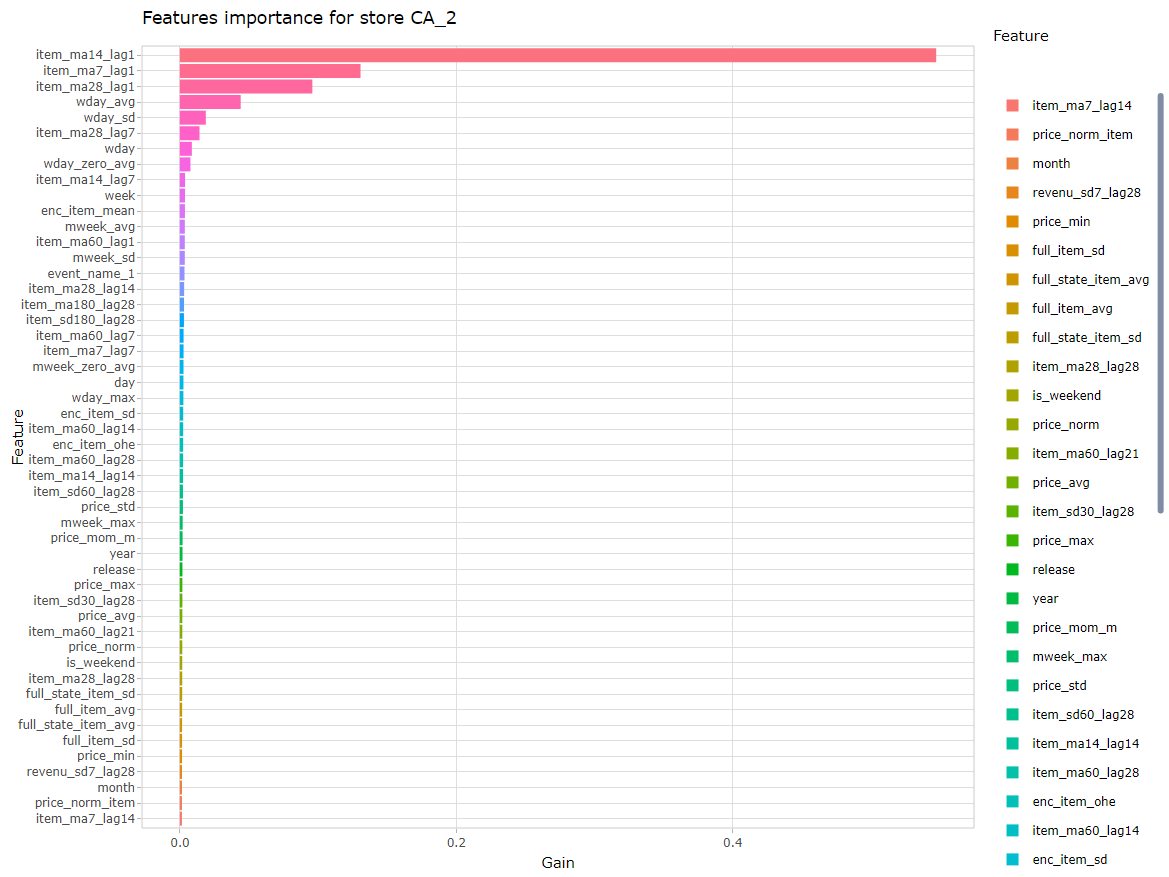
Importance des variables
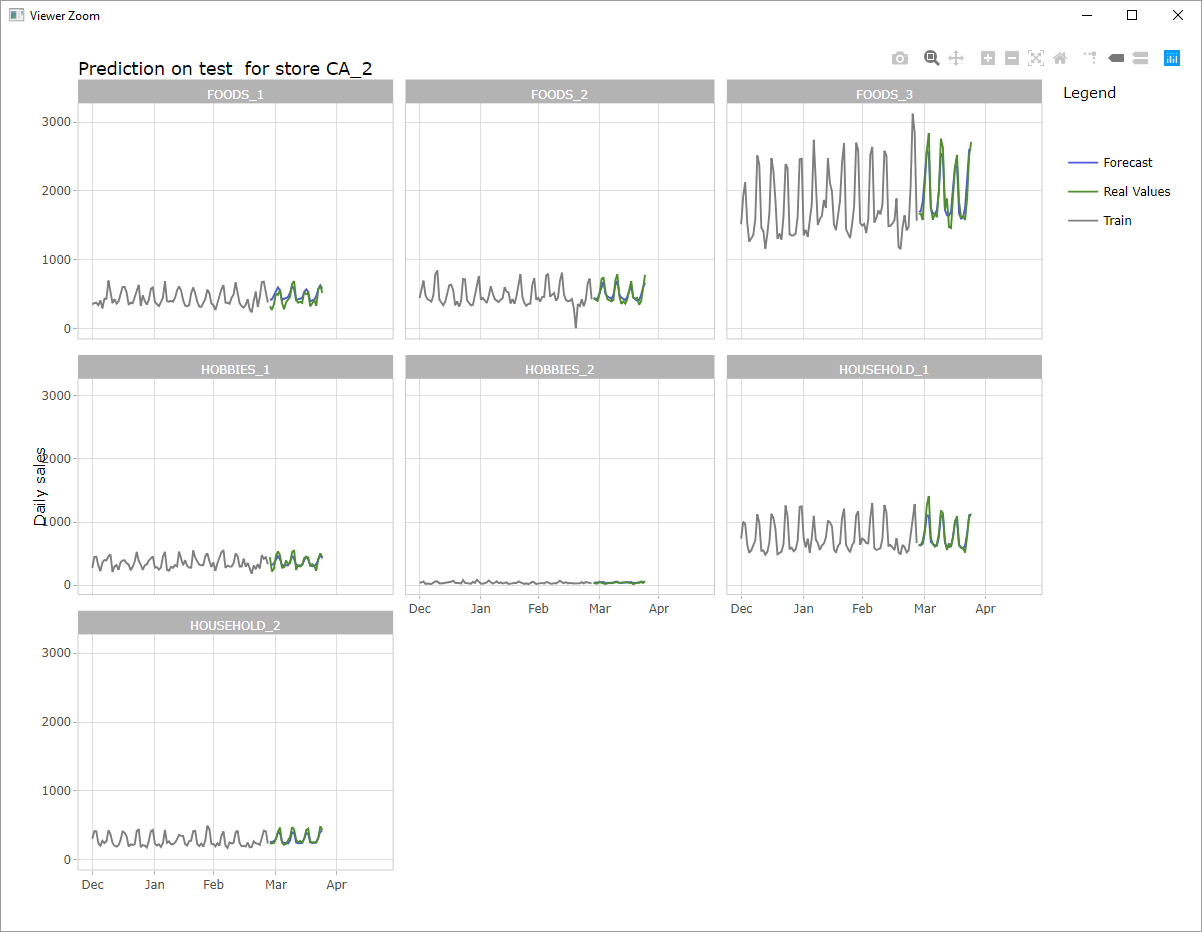
Prévisions pour tous les départments
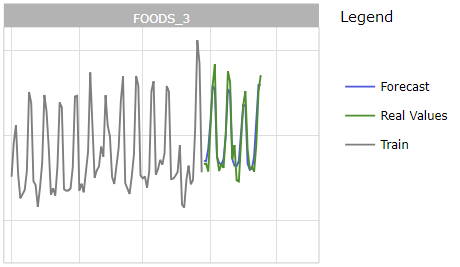
Zoom sur un départment sur les données de validation
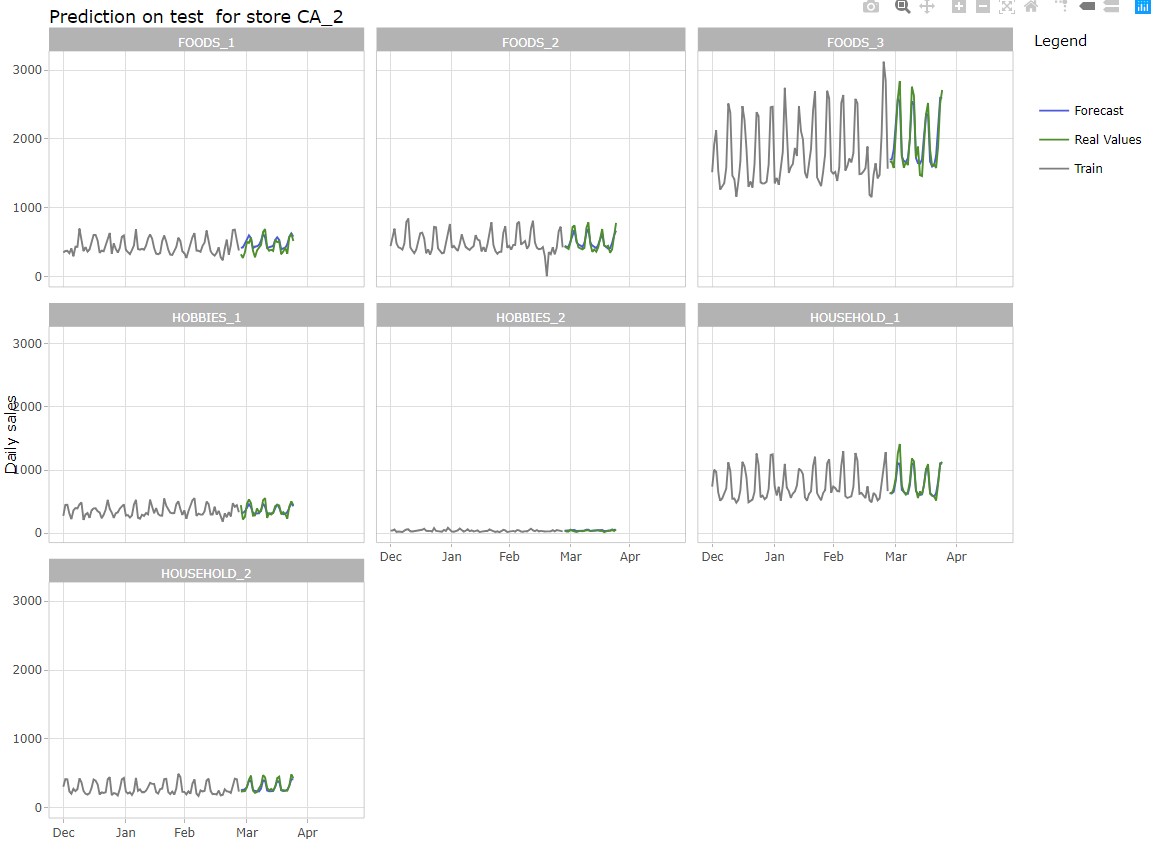
Prévisions pour tous les départments
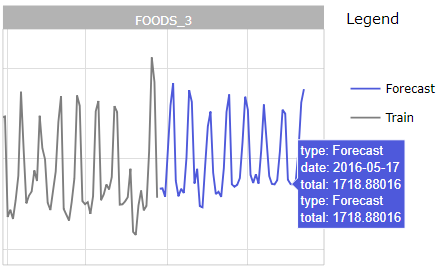
Zoom sur un départment sur les données d’évaluation
Le script imprime également dans la console de nombreuses informations pour savoir quelle est l’étape en cours dans le programme.
Version automatisée
La version automatisée imprime les mêmes informations dans la console pour faciliter la vérification régulière du fonctionnement du programme.
Il écrit également un fichier performance_xx_x.csv avec le RMSE pour chaque magasin et un fichier features_xx_x.csv avec l’importance des variablesé (où xx_x est le store_id).
Algorithme
Voici une description simple de l’algorithme :
Note 1: Pour ces prévisions, toutes les données (sauf les valeurs à prévoir bien sûr) sont connues à l’avance. Ce sont les mêmes états, magasins, catégories, départements, articles et toutes les données de calendrier et de prix sont disponibles pour le mois suivant, qui est la période à prévoir. Par conséquent, il est possible de faire l’ingénierie des fonctionnalités sur toutes les données, avant la séparation entre le test et l’apprentissage, et d’utiliser le même dataframe pour la validation et l’évaluation. C’est pourquoi je peux enregistrer et charger les données pour les deux périodes, au lieu de devoir réexécuter la partie ingénierie des fonctionnalités.
Note 2: Vous pouvez réentraîner le modèle sur l’ensemble de données complet (jusqu’au 2016-05-22) avant de prédire, ou utiliser le modèle entraîné uniquement sur les données de test (laissant sur un écart d’un mois). La deuxième méthode a mieux fonctionné pour la période d’évaluation et est plus rapide car le modèle n’est également entraîné qu’une seule fois. Pour utiliser la première méthode, dé-commentez la partie correspondante dans la section principale du script.
Résultats
Score obtenu pour la compétition
Cette solution telle quelle sur le référentiel github donne un score public (WMRSSE) de 0,48734 et un score privé de 0,62408, ce qui donnerait une position de 190ème sur 5558 participants, ce qui se situe dans le top 4% et une médaille d’argent pour cette compétition . C’est l’état du modèle depuis la dernière soumission que j’ai faite le dernier jour du concours.
Habituellement, pour les compétitions sur Kaggle, nous avons droit à 2 soumissions, et nous pouvons en soumettre une agressive et une plus conservatrice. Malheureusement pour cette compétition, il n’y avait qu’une seule soumission autorisée, et j’ai décidé d’utiliser une soumission précédente qui avait un meilleur score dans le classement public (0.46744), mais cela n’a pas été aussi bien pour le score privé : 0.66695, ce qui est la 385ème place sur 5558, qui est dans le top 7% et une médaille de bronze.
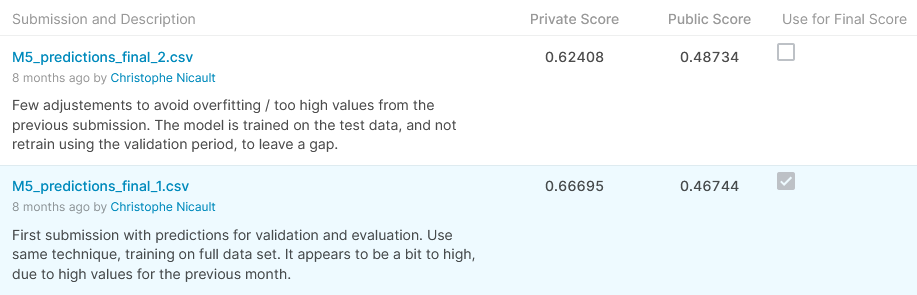
Score on Kaggle
Il y a eu un énorme bouleversement des scores pour cette compétition avec des résultats différents entre le classement public et le classement privé. Cela s’explique en partie par la différence entre cette période et les années précédentes. Pour les 5 années précédentes, les ventes de juin ont toujours augmenté par rapport aux ventes de mai. La tendance était à la hausse au cours du mois précédent et la plupart des modèles étaient optimistes sur le volume des ventes. Pour la période de validation, de nombreuses équipes ont utilisé un coefficient multiplicateur pour refléter cette tendance dans les prévisions, conduisant à un meilleur score pour les données publiques, mais ne fonctionnant que pour cette période.
Visualisation à différents niveaux
Vous trouverez ci-dessous quelques visualisations pour comparer les prévisions aux valeurs réelles, à différents niveaux d’agrégation. Les valeurs réelles ont été divulguées après la fin du concours.
Agrégation au niveau de l’état pour la Californie et au niveau du magasin pour le magasin CA_2
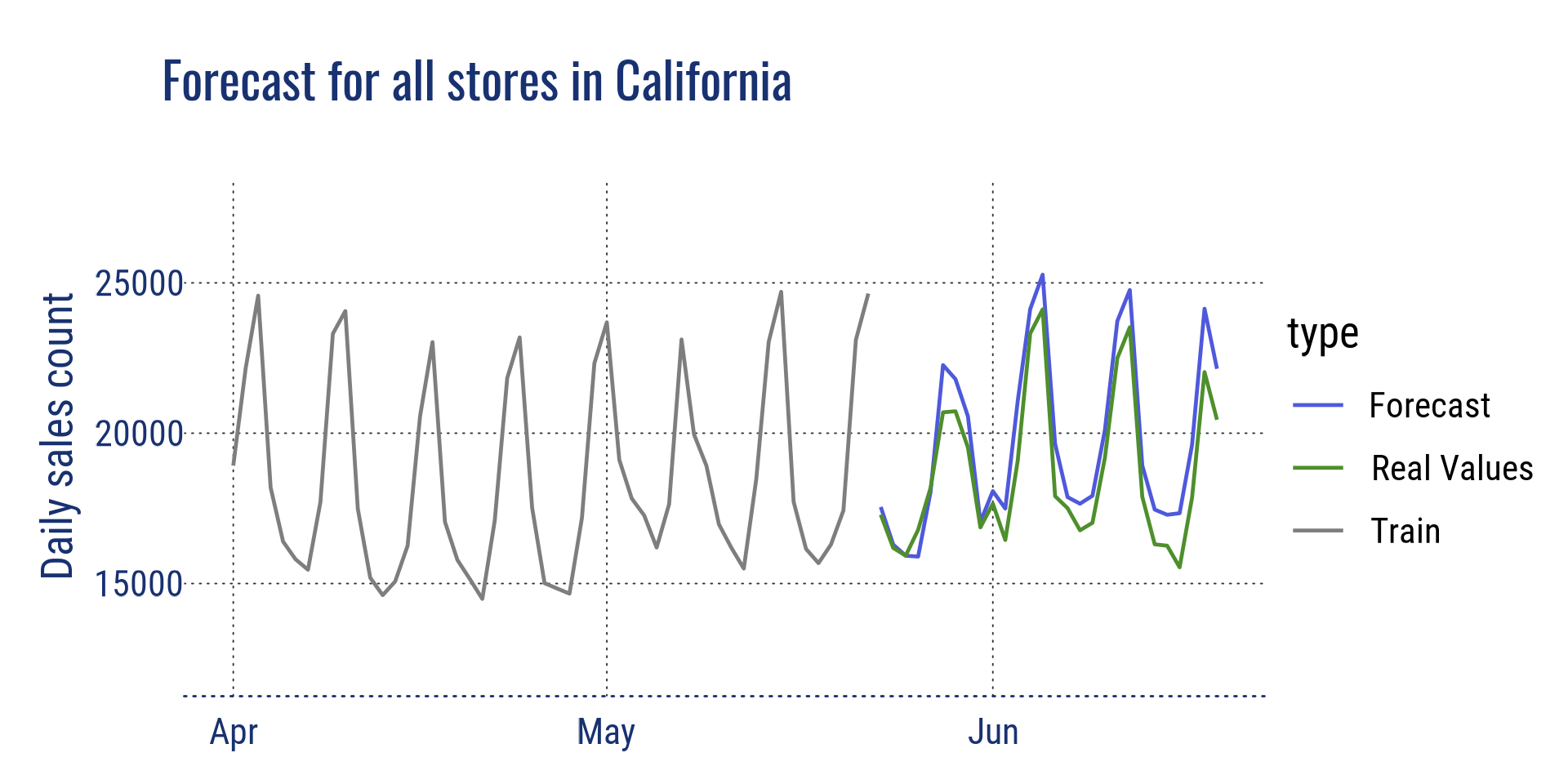
Prévisions pour tous les magasins en Californie
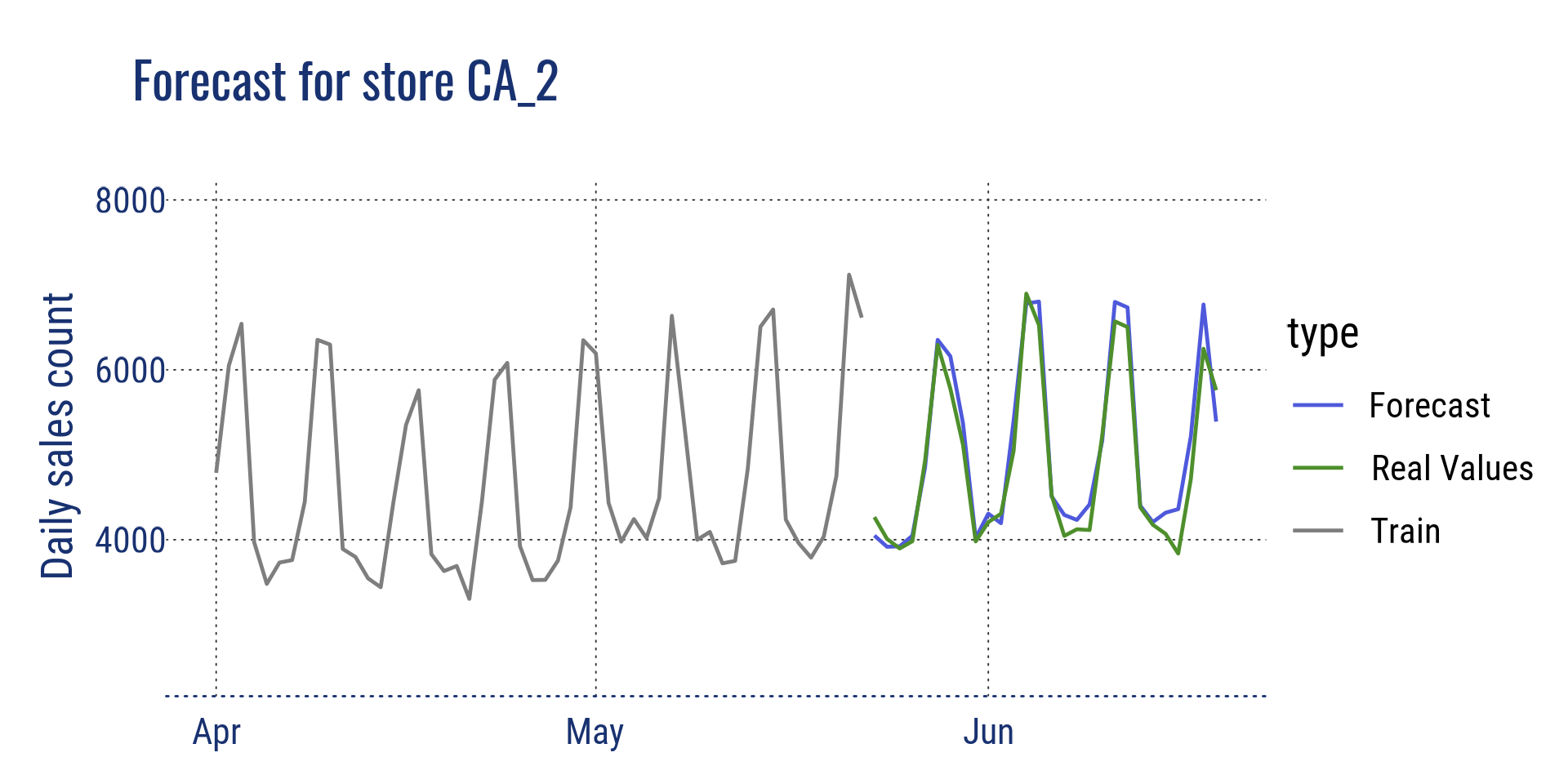
Prévision pour le magasin CA_2
Agrégation au niveau catégorie pour le magasin CA_2 et au niveau département pour le magasin CA_2
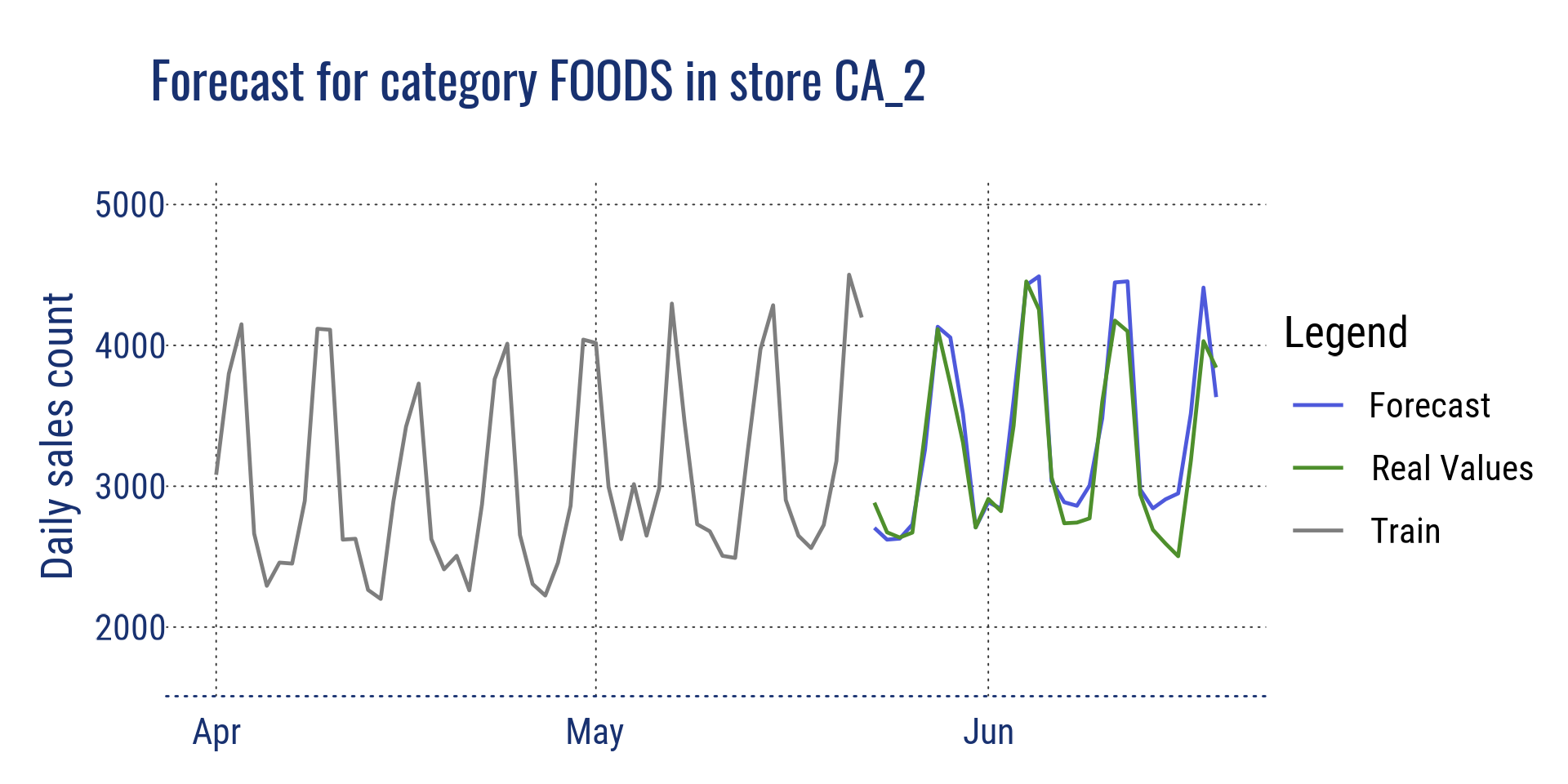
Prévision pour la catégorie FOODS dans le magasin CA_2
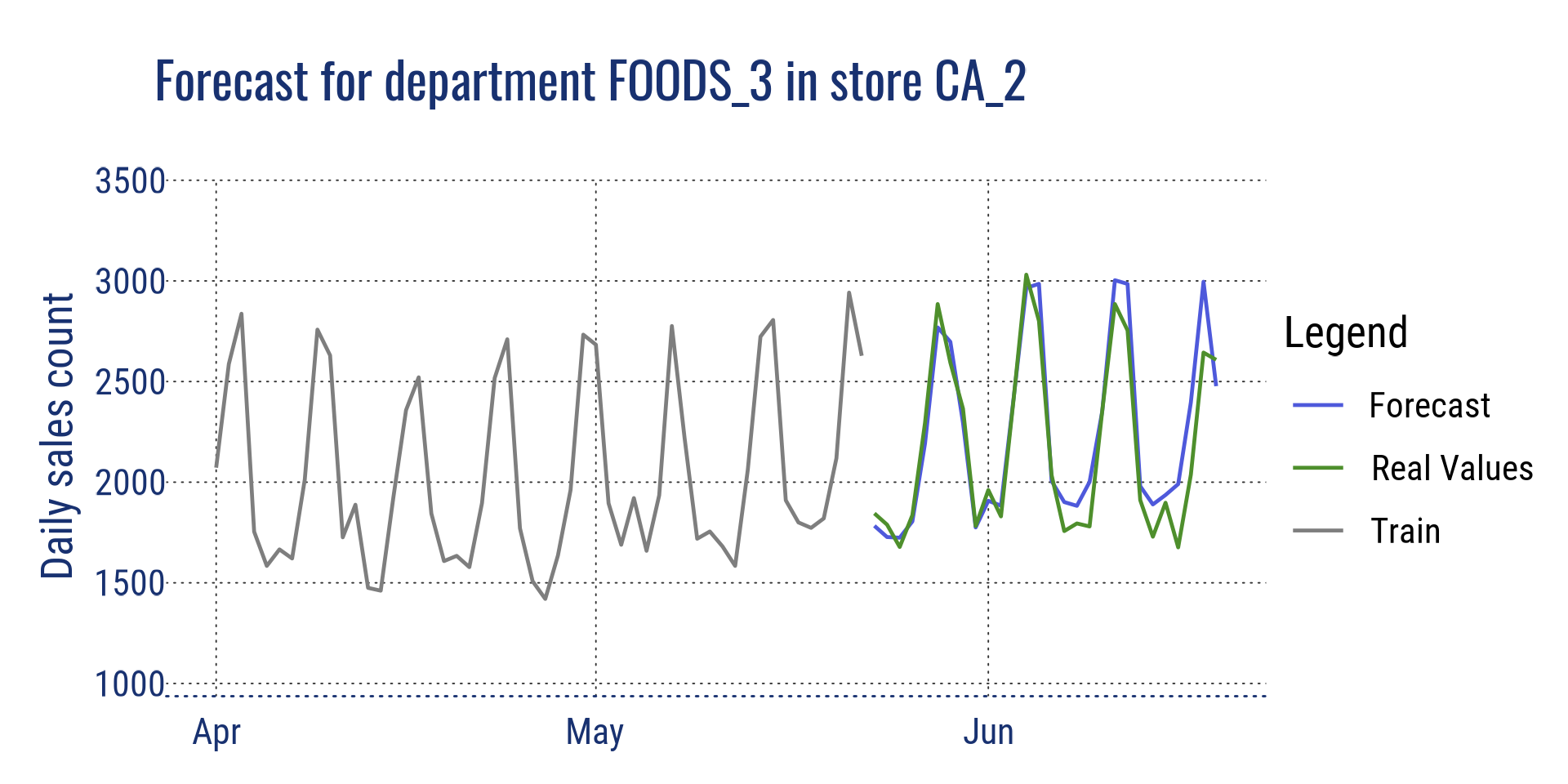
Prévision pour le département FOODS_3 en CA_2
Agrégation au niveau de l’article pour tous les magasins en Californie et pour un seul article dans le magasin CA_2
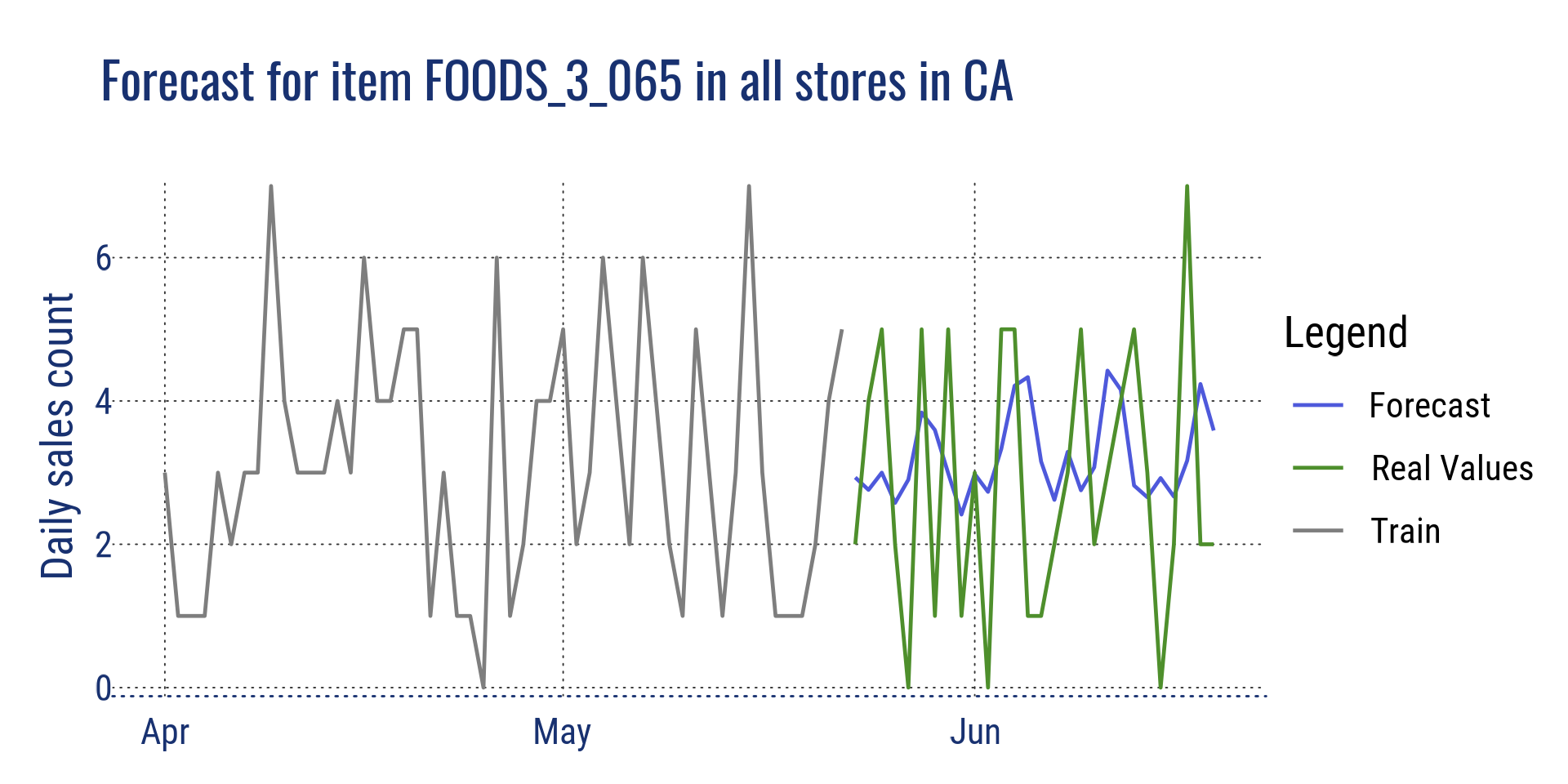
Prévision pour l’article FOODS_3_065 dans tous les magasins en Californie
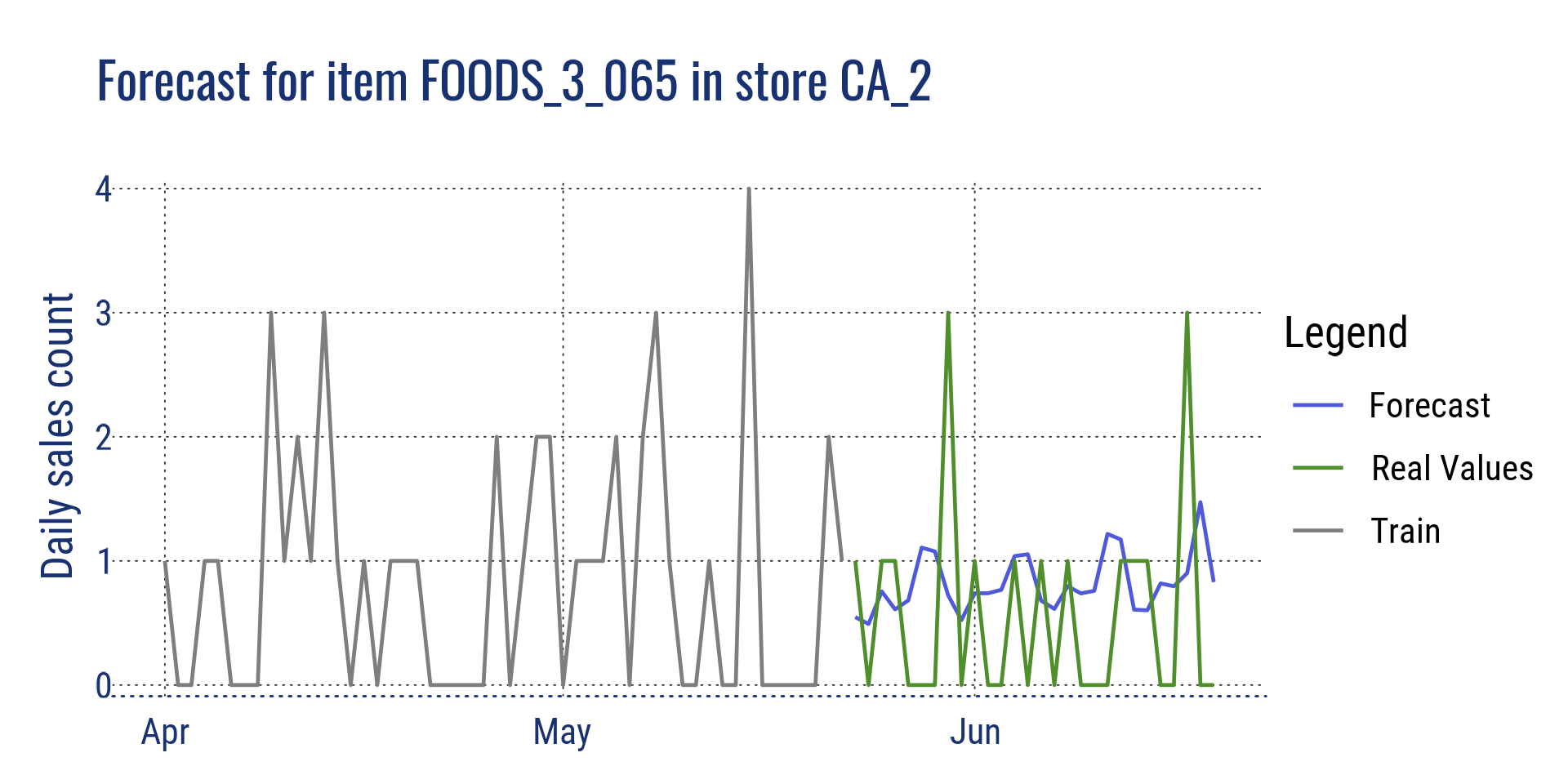
Prévision pour l’article FOODS_3_065 dans CA_2
Références (Anglais)
Ma solution pour la compétition: https://github.com/cnicault/m5-forecasting-accuracy
Compétition sur Kaggle: https://www.kaggle.com/c/m5-forecasting-accuracy/overview
Méthodes gagnantes (Python): https://github.com/Mcompetitions/M5-methods
Jeu de données avec les valeurs réelles: https://drive.google.com/drive/folders/1D6EWdVSaOtrP1LEFh1REjI3vej6iUS_4?usp=sharing
LightGBM: https://lightgbm.readthedocs.io/en/latest/
Christophe Nicault
Stratégie des Systèmes d’Information
Transformation Numérique
Data Science
Je travaille sur la stratégie des systèmes d’information, les projets informatiques et la science des données.
Comment l’exécuter ?
Toutes les étapes nécessaires à l’exécution des scripts pour entraîner les modèles, prédire la période de prévision et fusionner les prévisions sont expliquées en détail sur mon dépôt github.
Les données sont à télécharger sur Kaggle ou sur le dépôt du concours, les liens sont en bas de cet article dans la rubrique “références”.